正则匹配原理
NFA匹配引擎基础
NFA 非确定型有穷自动机,支持回溯,它的特点主要是提供longest-leftmost匹配,也就是在找到最左侧最长匹配之前,它将继续回溯
大部分语言使用都是NFA正则匹配引擎
字符串组成
字符串的组成,由字符和位置组成"abc"包含了三个字符和4个位置

字符串匹配的时候,不仅要匹配字符,还要匹配字符的位置
占有字符和零宽度
正则表达式:^abc
1 '^'匹配一个字符串的开头,匹配的是0位置,匹配的结果也不会保存到最终的结果中,所以"^"就是零宽度的正则匹配
2 "a"匹配的字符串a,匹配的结果会保存到最终的匹配结果中,这种正则字符"a"就是占有字符, b开始匹配的时候匹配是a匹配后的下个字符串
占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。
理解占有字符和零宽度,帮助理解一个正则表达式有至关重要的
控制权
源字符串:"abcd"
正则表达式: "^abc" 这个表达式可以看做4个子表达式(^)(a)(b)(c)
匹配过程中第一个表达式获取控制权,从字符串某一位置开始匹配 一个子表达式开始尝试匹配的位置,是从前一子表达匹配成功的结束位置开始的
所以(^)匹配的是0位置,匹配成功后,把控制权给了表达式(a), 因为(^)匹配的是位置,并不匹配字符串,所有(a)还是匹配第一个字符串a, 匹配完成后,控制权交给下一个子表达式(b),以此类推
(子表达式一)(子表达式二)
假设(子表达式一)为零宽度表达式,由于它匹配开始和结束的位置是同一个,如位置0,那么(子表达式二)是从位置0开始尝试匹配的。
假设(子表达式一)为占有字符的表达式,由于它匹配开始和结束的位置不是同一个,如匹配成功开始于位置0,结束于位置2,那么(子表达式二)是从位置2开始尝试匹配的
回溯
源字符串: "abc"
正则匹配字符串: ".*"
当(")匹配完成后,把控制权给到正则表达式(.*),由于它是贪婪模式,他会尽可能多的匹配源字符串,所以他会匹配到abc",也就是把整个字符串都匹配完了,这个时候把控制权给到("),这个时候它发现字符串都匹配完了,所以(")匹配失败,这个时候怎么办
回溯,就是(.*)吐出一个字符出来给子表达式(")去匹配,这个过程就叫做回溯
子表达式(.*)吐出了字符", 子表达式(")刚好匹配字符", 所以匹配成功
如果子表达式(")匹配不成功,会让(.)接着吐字符出来,直到子表达式(")匹配成功,如果子表达式(.)已经把所有的字符都吐出来了,子表达式(")还是没有匹配成功,则整个表达式匹配失败
传动
源字符串:my name is "sunny"
正则表达式: "sunny"
首先子表达式(")开始匹配字符m, 发现匹配失败了,那这个时候怎么办,正则引擎传动装置使正则向前传动,进入下一轮尝试, 然后子表达式(")开始匹配字符y, 匹配依然失败,正则在向前传动,直到匹配都字符"
这个过程就是传动
正则表达式简单匹本过程
源字符串:abc
正则表达式:abc
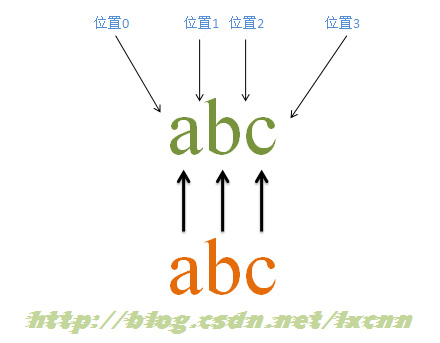 匹配过程:
匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b”;由于“a”已被“a”匹配,所以“b”从位置1开始尝试匹配,由“b”来匹配“b”,匹配成功,控制权交给“c”;由“c”来匹配“c”,匹配成功。 此时正则表达式匹配完成,报告匹配成功。匹配结果为“abc”,开始位置为0,结束位置为3
含有匹配优先量词的匹配过程——匹配成功
源字符串:ac
正则表达式:ab?c
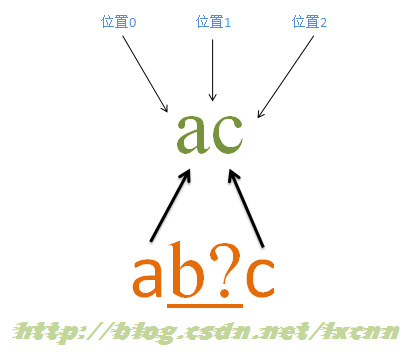
匹配过程: 首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b?”;先尝试进行匹配,由“b?”来匹配“c”,同时记录一个备选状态,匹配失败,此时进行回溯,找到备选状态,“b?”忽略匹配,让出控制权,把控制权交给“c”;由“c”来匹配“c”,匹配成功。 此时正则表达式匹配完成,报告匹配成功。匹配结果为“ac”,开始位置为0,结束位置为2。其中“b?”不匹配任何内容。
需要注意的是子表达式(b?)会优先匹配字符,(?)也是贪婪表达式
含有匹配优先量词的匹配过程——匹配失败
源字符串:abd
正则表达式:ab?c
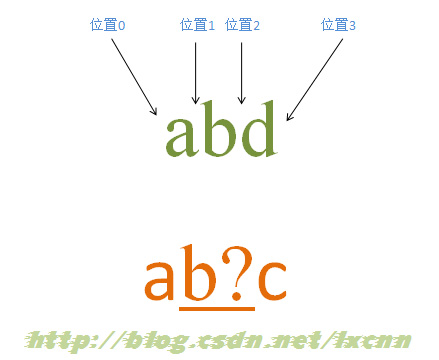 匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b?”;先尝试进行匹配,由“b?”来匹配“b”,同时记录一个备选状态,匹配成功,控制权交给“c”;由“c”来匹配“d”,匹配失败,此时进行回溯,找到记录的备选状态,“b?”忽略匹配,即“b?”不匹配“b”,让出控制权,把控制权交给“c”;由“c”来匹配“b”,匹配失败。此时第一轮匹配尝试失败。
匹配过程:
首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b?”;先尝试进行匹配,由“b?”来匹配“b”,同时记录一个备选状态,匹配成功,控制权交给“c”;由“c”来匹配“d”,匹配失败,此时进行回溯,找到记录的备选状态,“b?”忽略匹配,即“b?”不匹配“b”,让出控制权,把控制权交给“c”;由“c”来匹配“b”,匹配失败。此时第一轮匹配尝试失败。
当第一轮匹配失败后,正则表达式会向前传动
正则引擎使正则向前传动,由位置1开始尝试匹配,由“a”来匹配“b”,匹配失败,没有备选状态,第二轮匹配尝试失败。
继续向前传动,直到在位置3尝试匹配d失败,匹配结束。此时报告整个表达式匹配失败
含有忽略优先量词的匹配过程——匹配成功
源字符串:abc
正则表达式:ab??c
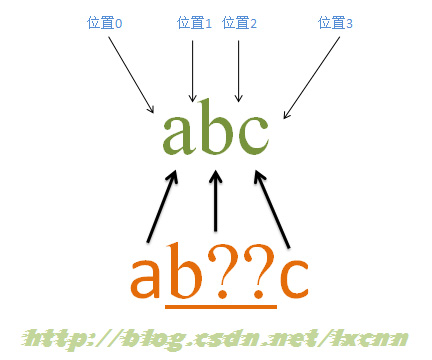
量词“??”属于忽略优先量词,在可匹配可不匹配时,会先选择不匹配,只有这种选择会使整个表达式无法匹配成功时,才会尝试进行匹配。这里的量词“??”是用来修饰字符“b”的,所以“b??”是一个整体。 匹配过程: 首先由字符“a”取得控制权,从位置0开始匹配,由“a”来匹配“a”,匹配成功,控制权交给字符“b??”;先尝试忽略匹配,即“b??”不进行匹配,同时记录一个备选状态,控制权交给“c”;由“c”来匹配“b”,匹配失败,此时进行回溯,找到记录的备选状态,“b??”尝试匹配,即“b??”来匹配“b”,匹配成功,把控制权交给“c”;由“c”来匹配“c”,匹配成功。 此时正则表达式匹配完成,报告匹配成功。匹配结果为“abc”,开始位置为0,结束位置为3。其中“b??”匹配字符“b”。
零宽度匹配过程
源字符串:a12
正则表达式:^(?=[a-z])[a-z0-9]+$
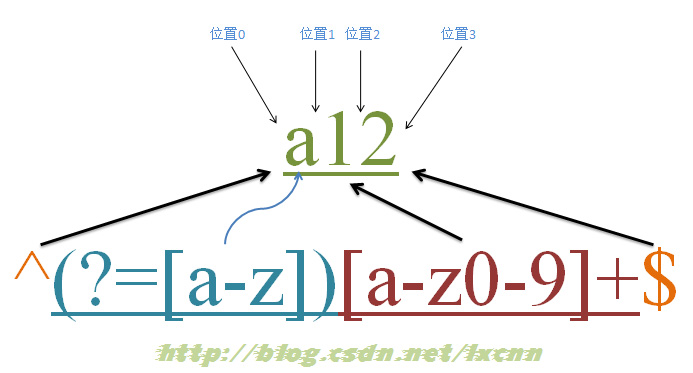
元字符“^”和“$”匹配的只是位置,顺序环视“(?=[a-z])”只进行匹配,并不占有字符,也不将匹配的内容保存到最终的匹配结果,所以都是零宽度的。 这个正则的意义就是匹配由字母或数字组成的,第一个字符是字母的字符串。 匹配过程: 首先由元字符“^”取得控制权,从位置0开始匹配,“^”匹配的就是开始位置“位置0”,匹配成功,控制权交给顺序环视“(?=[a-z])”; “(?=[a-z])”要求它所在位置右侧必须是字母才能匹配成功,零宽度的子表达式之间是不互斥的,即同一个位置可以同时由多个零宽度子表达式匹配,所以它也是从位置0尝试进行匹配,位置0的右侧是字符“a”,符合要求,匹配成功,控制权交给“[a-z0-9]+”; 因为“(?=[a-z])”只进行匹配,并不将匹配到的内容保存到最后结果,并且“(?=[a-z])”匹配成功的位置是位置0,所以“[a-z0-9]+”也是从位置0开始尝试匹配的,“[a-z0-9]+”首先尝试匹配“a”,匹配成功,继续尝试匹配,可以成功匹配接下来的“1”和“2”,此时已经匹配到位置3,位置3的右侧已没有字符,这时会把控制权交给“$”; 元字符“$”从位置3开始尝试匹配,它匹配的是结束位置,也就是“位置3”,匹配成功。 此时正则表达式匹配完成,报告匹配成功。匹配结果为“a12”,开始位置为0,结束位置为3。其中“^”匹配位置0,“(?=[a-z])”匹配位置0,“[a-z0-9]+”匹配字符串“a12”,“$”匹配位置3。
贪婪和非贪婪
贪婪模式:在保证匹配成功的状态下,尽可能多的匹配
“{m,n}”、“{m,}”、“?”、“*”和“+”
非贪婪: 在保证匹配成功的状态下,在尽可能少的匹配
“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”
比如说"+"的原意是匹配1到多个,如果是贪婪模式,他会尽可能的匹配多个,如果是非贪婪模式,他只会匹配一个
比如说"?"的原意是匹配0或者1个,如果是贪婪模式,他会尽可能的匹配1哥,如果是非贪婪模式,他就不匹配了
注意:这些选择都是需要保证匹配成功,也就是说最终如果"??"不匹配使得整个正则表达式匹配不成功,那么久需要回溯,尝试匹配
从基本匹配原理谈起
源字符串:"Regex"
正则表达式:".*"
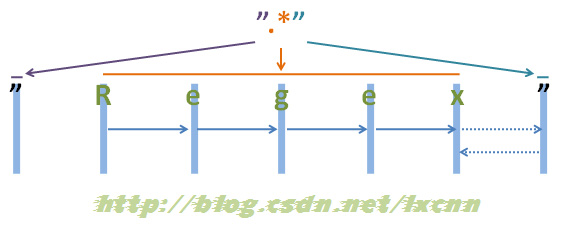
注:为了能够看清晰匹配过程,上面的空隙留得较大,实际源字符串为“”Regex””,下同。 来看一下匹配过程。首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.”。 “.”取得控制权后,由于“”是匹配优先量词,在可匹配可不匹配的情况下,优先尝试匹配。从位置1处的“R”开始尝试匹配,匹配成功,继续向右匹配,匹配位置2处的“e”,匹配成功,继续向右匹配,直到匹配到结尾的“””,匹配成功,由于此时已匹配到字符串的结尾,所以“.”结束匹配,将控制权交给正则表达式最后的“"”。 “"”取得控制权后,由于已经在字符串结束位置,匹配失败,向前查找可供回溯的状态,控制权交给“.”,由“.”让出一个字符,也就是字符串结尾处的“””,再把控制权交给正则表达式最后的“"”,由“"”匹配字符串结尾处的“"”,匹配成功。 此时整个正则表达式匹配成功,其中“.*”匹配的内容为“Regex”,匹配过程中进行了一次回溯
非贪婪模式简单的匹配过程
源字符串:"Regex"
正则表达式:".*?"
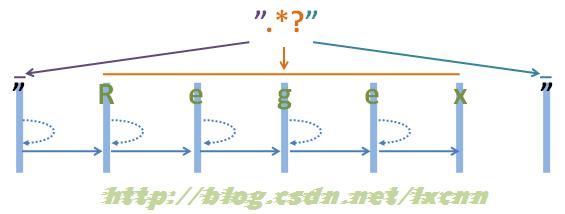
看一下非贪婪模式的匹配过程。首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.?”。 “.?”取得控制权后,由于“?”是忽略优先量词,在可匹配可不匹配的情况下,优先尝试不匹配,由于“”等价于“{0,}”,所以在忽略优先的情况下,可以不匹配任何内容。从位置1处尝试忽略匹配,也就是不匹配任何内容,将控制权交给正则表达式最后的“””。 “"”取得控制权后,从位置1处尝试匹配,由“"”匹配位置1处的“R”,匹配失败,向前查找可供回溯的状态,控制权交给“.?”,由“.?”吃进一个字符,匹配位置1处的“R”,再把控制权交给正则表达式最后的“"”。 “"”取得控制权后,从位置2处尝试匹配,由“"”匹配位置1处的“e”,匹配失败,向前查找可供回溯的状态,重复以上过程,直到由“.?”匹配到“x”为止,再把控制权交给正则表达式最后的“"”。 “"”取得控制权后,从位置6处尝试匹配,由“"”匹配字符串最后的“"”,匹配成功。 此时整个正则表达式匹配成功,其中“.?”匹配的内容为“Regex”,匹配过程中进行了五次回溯
效率最优
源字符串:"Regex"
给出正则表达式三:"[^"]*"
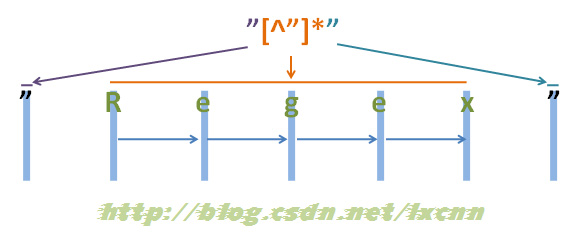
首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“"”。 “"”取得控制权后,由于“”是匹配优先量词,在可匹配可不匹配的情况下,优先尝试匹配。从位置1处的“R”开始尝试匹配,匹配成功,继续向右匹配,匹配位置2处的“e”,匹配成功,继续向右匹配,直到匹配到“x”,匹配成功,再匹配结尾的“””时,匹配失败,将控制权交给正则表达式最后的“"”。 “””取得控制权后,匹配字符串结尾处的“””,匹配成功。 此时整个正则表达式匹配成功,其中“"”匹配的内容为“Regex”,匹配过程中没有进行回溯。 将量词修饰的子表达式由范围较大的“.”,换成了排除型字符组“"”,使用的仍是贪婪模式,很完美的解决了需求和效率问题。当然,由于这一匹配过程没有进行回溯,所以也不需要记录回溯状态,这样就可以使用固化分组,对正则做进一步的优化。 给出正则表达式四:"(?>")" 固化分组并不是所有语言都支持的,如.NET支持,而Java就不支持,但是在Java中却可以使用更简单的占有优先量词来代替:""+"。
贪婪和非贪婪只是影响效率,不会影响结果
理解了以上之后,基本上能应付大部分的正则表达式需求