Engine Configuration
Engine 是访问数据库的入口,Engine引用Connection Pool和 Dialect实现了对数据库的访问, Dialect指定了具体的数据库类型 MYSQL, SQLSERVER等, 三者关系如图所示:
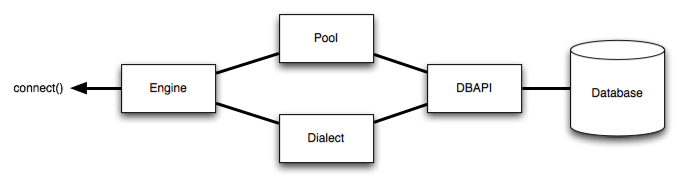
只有当调用connect(),execute()函数的时候,才会创建数据库的连接
create_engine
使用 create_engine创建我们需要的DB starting point
from sqlalchemy import create_engine
scheme = 'mysql+pymysql://root:123456@localhost:3306/dev_shopping?charset=utf8'
engine = create_engine(scheme, pool_size=10 , max_overflow=-1, pool_recycle=1200)
create_engine 函数常用参数:
pool_size=10 # 连接池的大小,0表示连接数无限制
pool_recycle=-1 # 连接池回收连接的时间,如果设置为-1,表示没有no timeout, 注意,mysql会自动断开超过8小时的连接,所以sqlalchemy沿用被mysql断开的连接会抛出MySQL has gone away
max_overflow=-1 # 连接池中允许‘溢出’的连接个数,如果设置为-1,表示连接池中可以创建任意数量的连接
pool_timeout=30 # 在连接池获取一个空闲连接等待的时间
echo=False # 如果设置True, Engine将会记录所有的日志,日志默认会输出到sys.stdout
创建Engine之后,接下来的问题,就是如何使用Engine
在单进程中,建议在在初始化的模块的时候创建Engine, 使Engine成为全局变量, 而不是为每个调用Engine的对象或者函数中创建, Engine不同于connect, connect函数会创建数据库连接的资源,Engine是管理connect创建的连接资源
在多进程中,为每个子进程都创建各自的Engine, 因为进程之间是不能共享Engine
connect
使用connect 创建连接数据库资源, 如上所说,即使创建了Engine, 还是没有创建对数据库的连接,调用connect才会创建真正的连接
connection = engine.connect()
result = connection.execute("select * from tmp")
print type(result) # <class 'sqlalchemy.engine.result.ResultProxy'>
for row in result:
print "target_name:", row['target_name']
connection.close()
这里有两个问题需要搞清楚,result返回对象类型和对象提供的方法,第二个是close函数调用之后,发生了什么事情,先说close
close
当调用connection.close()之后,由connect函数创建的连接会被释放到连接池中, 可以供下次使用.
上面这段代码可以简写为:
result = engine.execute("select username from users")
for row in result:
print "username:", row['username']
execute函数会创建自己的连接,并执行声明的sql语句,返回ResultProxy对象,在这个情况下,ResultProxy会有个标记close_with_result, 如果ResultProxy的值被全部取出来,Engine会自动close本次连接,并把连接释放到连接池里面去
如果ResultProxy里面还有数据没有取出来(rows remaining),可使用result.close()释放本次连接,如果没有使用result.close()释放连接,python garbage collection 最终为释放本次连接到连接池中
ResultProxy
现在来看一下execute()执行之后返回的结果类型 详细文档。
常用的API如下:
fetchone() 取出一行, 当所有的行被取出来之后 connect resource会被释放到连接池中,再次调用fetchone()将返回None
result = connection.execute("select * from tmp")
row = result.fetchone()
print row[0] # access via integer position
print row['id'] # access via name
print type(row) # <class 'sqlalchemy.engine.result.RowProxy'>
# 类似还有
first() 获取第一行,同时无条件的释放连接
scalar() 获取第一行第一列的数据,同时无条件的释放连接
rowcount 获取row count
lastrowid 使用insert()方法的时候,获取最后一行的id
到目前为止,我们学会了如何去创建Egnine并使用Engine执行简单的sql语句,现在还有两个问题
一,我们还没有涉及到的是如何使用sqlalchemy提供的API去构建insert, update, delete, create table等相应的SQL
二,当我们使用insert, update等sql的时候sqlalchemy是否使用到事物,如何使用事物。
先从第二个问题说起
Using Transactions
This section describes how to use transactions when working directly with Engine and Connection objects. When using the SQLAlchemy ORM, the public API for transaction control is via the Session object, which makes usage of the Transaction object internally. See Managing Transactions for further information
Connection对象提供了一个begin()函数返回Transaction对象
connection = engine.connect()
trans = connection.begin()
try:
r1 = connection.execute(table1.select())
connection.execute(table1.insert(), col1=7, col2='this is some data')
trans.commit()
except:
trans.rollback()
raise
上面代码可以简写为:
with engine.begin() as connection:
r1 = connection.execute(table1.select())
connection.execute(table1.insert(), col1=7, col2='this is some data')
在一次连接中,两个函数同时开启了事物
# method_a starts a transaction and calls method_b
def method_a(connection):
trans = connection.begin() # open a transaction
try:
method_b(connection)
trans.commit() # transaction is committed here
except:
trans.rollback() # this rolls back the transaction unconditionally
raise
# method_b also starts a transaction
def method_b(connection):
trans = connection.begin() # open a transaction - this runs in the context of method_a's transaction
try:
connection.execute("insert into mytable values ('bat', 'lala')")
connection.execute(mytable.insert(), col1='bat', col2='lala')
trans.commit() # transaction is not committed yet
except:
trans.rollback() # this rolls back the transaction unconditionally
raise
# open a Connection and call method_a
conn = engine.connect()
method_a(conn)
conn.close()
当调用method_a()函数时开启事物,然后在调用methon_b, method_b也会开启事物,这时候会有一个计算器,记录开启事物的个数,当调用用commit()函数之后,计数器为减1,不管是method_a or method_b调用了rollback(), 整个事物都会回滚。只有当method_a调用了commit()之后,整个事物才算结束
Understanding Autocommit
在使用INSERT, UPDATE or DELETE, 如果没有声明Transaction,即如果没有开启事物 并且autocommit=True, SQLAlchemy会自动commit()执行SQL语句 如果没有设置这个参数,SQLAlchemy会根据正则表达式匹配出SQL语句里面的INSERT, UPDATE or DELETE 自动提交
result = connection.execution_options(autocommit=True).\
execute(stmt)
值得注意的是:
TAhe ORM, as the Session object by default always maintains an ongoing Transaction.
SQL Expression Language Tutorial
使用SQL的基础是创建Table
Define and Create Tables
>>> from sqlalchemy import Table, Column, Integer, String, MetaData, ForeignKey
>>> metadata = MetaData()
>>> users = Table('users', metadata,
... Column('id', Integer, primary_key=True),
... Column('name', String),
... Column('fullname', String),
... )
# users 即为返回的table类型,下面的insert, update等语句都需要使用到users
INSERT
ins = users.insert().values(name='jack', fullname='Jack Jones')
ins.compile().params # 获取插入的参数
result = conn.execute(ins) # 执行SQL
一次插入多个值
>>> conn.execute(addresses.insert(), [
... {'user_id': 1, 'email_address' : 'jack@yahoo.com'},
... {'user_id': 1, 'email_address' : 'jack@msn.com'},
... {'user_id': 2, 'email_address' : 'www@www.org'},
... {'user_id': 2, 'email_address' : 'wendy@aol.com'},
... ])
还有select等其他SQL可查看文档
以上接下来,我们需要了解ORM的知识点